Introduction to RoboKudo¶
RoboKudo is an open-source, knowledge-enabled perception framework designed to address the complex perception needs of mobile manipulation tasks in robotics. Built on the principles of Unstructured Information Management (UIM) and utilizing Behavior Trees (BTs), RoboKudo allows for the creation of flexible and task-specific perception processes. This makes it adaptable to a wide variety of tasks, such as object detection, scene understanding, and pose estimation, especially in dynamic environments like households.
The core concept of RoboKudo revolves around the Perception Pipeline Tree (PPT), which represents these perception processes as modular, hierarchical structures. PPTs enable robots to dynamically combine and execute state-of-the-art computer vision methods based on the requirements of the task and the capabilities of the robot’s sensors. This flexibility is crucial for solving diverse perception tasks—whether one-shot object detection or continuous tracking—through adaptable and scalable pipelines.
Key Features¶
RoboKudo seamlessly integrates computer vision methods with robotic perception systems, supporting several libraries and external tools for 2D and 3D data processing. The framework can directly handle:
2D Image Processing using OpenCV.
3D Data Processing using the Open3D library.
Integration with external vision algorithms via Docker Containers, ROS nodes, and ROS actions, ensuring compatibility across various platforms.
The system is designed to enable easy incorporation of new computer vision algorithms, as no single algorithm can solve all perception tasks effectively.
Annotators¶
A key component of the RoboKudo framework is the Annotator, which processes sensor data and generates annotations. Each annotator works within the framework’s Common Analysis Structure (CAS), a shared data structure that stores sensory inputs and generated annotations. Annotators communicate and exchange data via the CAS, ensuring modular and collaborative analysis across multiple vision methods.
For example, a collection reader annotator retrieves percepts from sensors and stores them in the CAS, while another annotator, such as the ImagePreprocessor, may generate a 3D point cloud from the sensor data for further analysis.
Common Analysis Structure (CAS)¶
The CAS is the core data exchange structure of RoboKudo, based on the UIM concept originally developed by IBM Watson. It allows flexible storage and retrieval of sensory data and their associated annotations, organized into Views. These views define the various types of sensory inputs or annotations (e.g., a color image), allowing annotators to access and manipulate relevant data.
This modularity enables efficient and dynamic perception pipelines where results from one annotator can be used by others, allowing the system to adapt to changing tasks in real time. For instance, annotations generated by an object detection annotator can be filtered or processed further to provide refined information like object pose or classification.
Pipelines¶
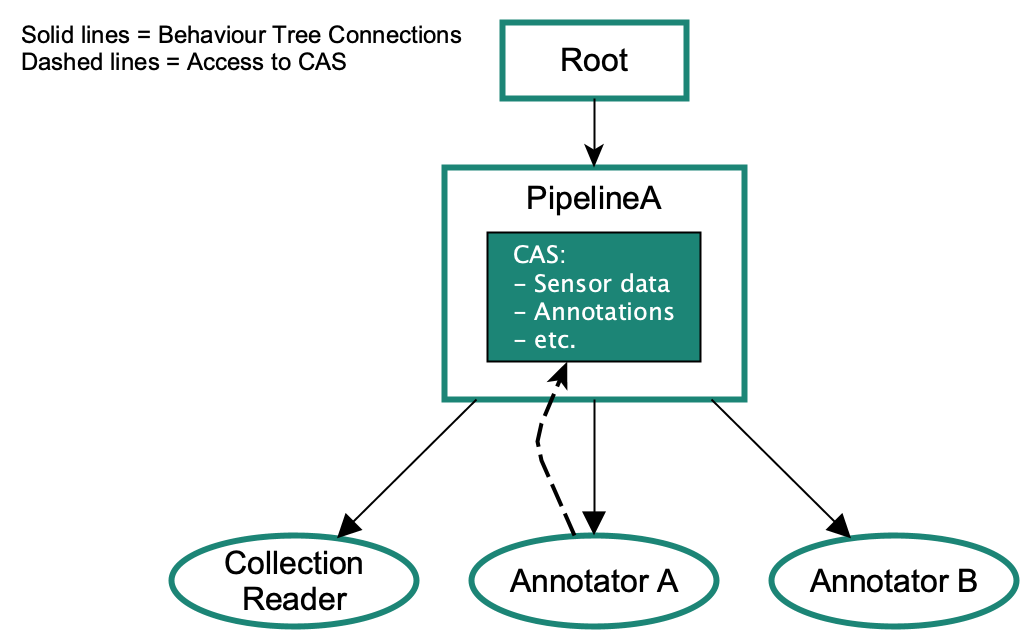
Pipelines in RoboKudo are specialized behavior tree sequences that organize and execute annotators for a specific perception task. Each pipeline is tied to a single CAS, ensuring that the data flow and annotations within the process are isolated and task-specific. This design enables flexible, task-centric perception processes, allowing multiple pipelines to run concurrently while maintaining clarity and modularity in the data structure.
Pipelines also provide built-in methods for introspection, visualization, and interaction between annotators. Annotators can access the CAS and other components of the pipeline, even if they are nested or running in parallel, ensuring seamless communication across the framework.
Annotations¶
Annotations in RoboKudo provide structured representations of the analysis performed on sensory data. Developers can extend the base Annotation class to define custom types of annotations, such as a classifications, color histogram for an object or a shape descriptor. These annotations allow the system to reason about similar types of data and adjust the perception process accordingly.
For example, an object detected in an image might be annotated with its color, shape, and size, and this information can be used by downstream annotators or decision-making components in the robot to refine actions like grasping or object manipulation.
GUI and Visualization¶
The graphical user interface (GUI) in RoboKudo is controlled through a behavior in the overall behavior tree. It features both 2D and 3D image viewers for visualizing the sensor data and the generated annotations. Annotator outputs, such as point clouds or object detections, can be visualized, providing real-time feedback during the perception process.
Users can interact with the GUI through key bindings to control the visualization modes or trigger specific analyses. This interactivity aids in debugging and fine-tuning perception pipelines by allowing users to directly inspect the annotator outputs during runtime.
Contributing¶
Get RoboKudo running on your system with a simple pipeline.
Read about the general concept of behavior trees. There is an excellent, comprehensive book on arxiv which can be seen here. But there are also many tutorials on YouTube on how to use behavior trees in general or practical applications on different problem domains like robotics and also games. Petter Ögren has a lot of good videos on his Youtube channel
Get familiar with the py_trees library after reading how behavior trees work. py_trees offers lots of documentation and also basic explanations of how behavior trees work. Going through the examples in the library will help you understand behavior trees even better and practice the concepts.
Set up your IDE to start development. Typically we recommend using PyCharm to do that. Check out the Installation chapter for details.
From here on it depends a bit on how you want to contribute to the project. If you’re working on the flow control of RoboKudo and therefore close to behavior trees, you should already be ready to start contributing. If you want to introduce new computer vision methods, we recommend looking into tutorials and documentation on using OpenCV and Open3D. Additionally, looking into their underlying concepts and libraries such as numpy, can be a huge benefit. If you want to develop fast computer vision methods in Python, you need to be at least familiar with how to quickly iterate over data structures by either using numpy operations or Numba.